Traditional Translation Management Systems (TMS) handle workflow logistics but still rely heavily on the translator’s cultural insight and deep knowledge of both source and target languages. In this blog post, we explore a modern architecture that integrates Large Language Models (LLMs), such as GPT-4o, with a traditional Translation Management System (TMS) to streamline and enhance the localization workflow. The workflow pipeline can ease this dependency, automate repetitive tasks, and enhance accuracy—resulting in a faster, smarter, and more reliable translation process.
Key Terms & Abbreviations
- TMS – Translation Management System: A platform that manages translation workflows, files, and collaboration between translators, reviewers, and project managers.
- TM – Translation Memory: A database that stores previously translated text segments for reuse.
- TB – Term Base: A glossary or dictionary of approved terms for consistent translation.
- CAT tool - Computer-Assisted Translation: is software used by translators to improve efficiency and consistency by leveraging translation memory (TM), term bases (TB), and other linguistic assets.
Traditional Localization
A Translation Management System (TMS) is essential in localization for games and applications because it streamlines and automates the complex process of adapting content for different languages and cultures. Games and apps often contain large volumes of dynamic text, frequent updates, and context-specific nuances that require precise handling to maintain user experience and brand consistency. A TMS centralizes translation workflows, enables collaboration among translators, developers, and project managers, and integrates with development pipelines to ensure faster turnaround times. Additionally, it helps manage terminology, maintain quality through reviews and version control, and supports scalability as projects grow. Without a TMS, localization can become error-prone, inefficient, and costly, ultimately impacting user satisfaction and market reach.
Within a TMS, the CAT tool serves as the translation interface—it’s where translators actually do the work. The TMS handles workflow management, file storage, version control, and collaboration, while the CAT tool is focused on assisting the translation process itself.
Key Functions of a CAT Tool in a TMS:
- Segmenting text into manageable units (sentences/phrases)
- Suggesting matches from Translation Memory (TM)
- Highlighting terminology from the Term Base (TB)
- Auto-propagation of repeated segments
- Built-in QA checks (e.g., number mismatches, punctuation, tag consistency, placeholder)
- Glossary enforcement and style guide integration
Popular CAT Tools (often embedded or integrated into TMSs):
- SDL Trados Studio
- MemoQ
- Memsource (Phrase)
- XTM
- Smartcat
- Wordfast
The common translation will include placeholder, it is usually variable, color and layout format definition. You can imagine it will look like:
Chinese:
欢迎回来,{username}!您上次登录是在 {last_login_time}。
English Translation:
Welcome back, {username}! Your last login was on {last_login_time}.The CAT tool can help you validation, it offers built-in support primarily for generic machine translation engines like Google Translate or Bing Translator.
These systems, while useful, do not leverage the contextual understanding and customization capabilities that LLMs like GPT-4o can provide. As a result, there’s a growing gap between the potential of AI-driven translation and what traditional CAT tools currently supports.
LLM-Powered approach to build Full Dictionary Term Base (FDTB)
Last year, I had my freelance work and focused on enhancing localization efficiency. At the time, GPT-4o stood out as a top contender among large language models due to its speed and accuracy. Its token usage was notably more efficient compared to GPT-4, and it demonstrated strong multilingual support. These advantages led me to prioritize an LLM-driven approach over traditional rule-based methods. The following diagram illustrates the architecture of a modern localization pipeline that integrates LLMs with a TMS which I have been working on:
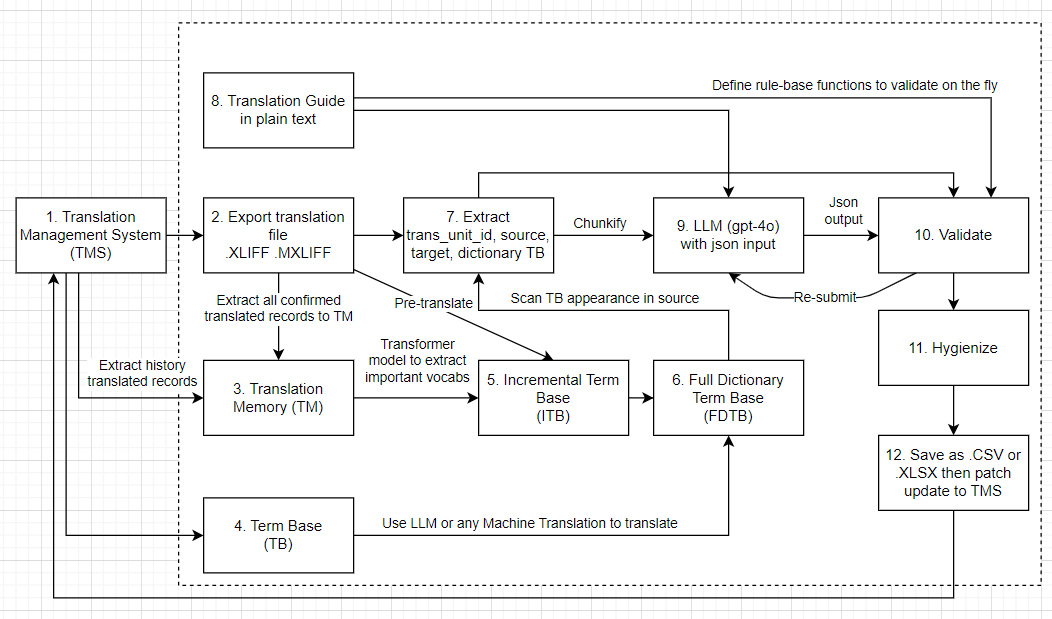
From step 1 to step 6, we will build a Full Dictionary Term Base (FDTB) that serves as the foundation for the localization process. This FDTB is crucial for ensuring that translations are consistent, context-aware, and aligned with evolving project needs.
1. Translation Management System (TMS)
The process begins with a Translation Management System (TMS) — the core platform that stores and manages all translation data. The TMS contains:
- Project files
- Translation Memories (TM)
- Approved Term Bases (TB)
The TMS acts as the central source of the project, ingesting translation data externaly and import back to TMs
2. Export Translation File
We export the translation project from the TMS in industry-standard formats like: .XLIFF /.MXLIFF
These files contain structured translation units — typically including source text, translated (target) text, and metadata such as segment ID or status. Reading there files are simple with following python code:
def read_mxliff(file_path):
"""
Sample MXLiff file structure:
<?xml version="1.0" encoding="UTF-8"?>
<xliff xmlns="urn:oasis:names:tc:xliff:document:1.2" xmlns:m="http://www.memsource.com/mxlf/2.0" version="1.2">
<file original="sample.txt" source-language="zh-CN" target-language="en-US" datatype="plaintext">
<body>
<group id="1" m:para-id="188">
<trans-unit id="w3cCVMTAQ0gkoeBP0_dc7:189" m:confirmed="0" m:created-at="0" m:created-by="" m:gross-score="0.0" m:level-edited="false" m:locked="false" m:modified-at="0" m:modified-by="" m:para-id="188" m:score="0.0" m:trans-origin="null" xml:space="preserve">
<source>士兵数量已达校场上限,只能再招募{1}名士兵</source>
<target>Maximum number of soldiers reached. You can only recruit {1} more soldiers.</target>
<alt-trans origin="machine-trans">
<target>Maximum soldiers reached, only {1} more can be recruited.</target>
</alt-trans>
<alt-trans origin="memsource-tm">
<target>Soldier count has reached the training ground limit, only {1} more can be recruited.</target>
</alt-trans>
<m:tunit-metadata>
<m:mark id="1">
<m:type>code</m:type>
<m:content>%s</m:content>
</m:mark>
</m:tunit-metadata>
</trans-unit>
</group>
</body>
</file>
</xliff>
"""
tree = ET.parse(file_path)
root = tree.getroot()
ns = {'n': 'urn:oasis:names:tc:xliff:document:1.2', 'm': 'http://www.memsource.com/mxlf/2.0'}
# Read group id, m:para-id, source, target
m = '{' + ns['m'] + '}'
list_data = []
for group in root.findall('.//n:group', ns):
group_id = group.get('id')
para_id = group.get(f'{m}para-id')
trans_units = group.findall('.//n:trans-unit', ns)
if len(trans_units) > 1:
raise Exception(f'More than 1 trans_unit: {group_id}, {para_id}')
for trans_unit in trans_units:
source = trans_unit.find('.//n:source', ns).text
target = trans_unit.find('.//n:target', ns).text if trans_unit.find('.//n:target', ns) is not None else None
converted_target = tn.normalize_text(target) if target is not None else None
if converted_target != target:
logging.info(f"Auto fixing composed word, Source: {source}, Target: {target}, Converted Target: {converted_target}")
target = converted_target
# trans-unit id, m:confirmed, m:locked
trans_unit_id = trans_unit.get('id')
confirmed = trans_unit.get(f'{m}confirmed') == '1'
locked = trans_unit.get(f'{m}locked') == 'true'
tunit_metadata_dict = {}
tunit_metadata = trans_unit.find(f'.//m:tunit-metadata', ns)
if tunit_metadata is not None:
marks = tunit_metadata.findall(f'.//m:mark', ns)
for mark in marks:
mark_id = mark.get('id')
mark_type = mark.find(f'.//m:type', ns).text
mark_content = mark.find(f'.//m:content', ns).text
tunit_metadata_dict[mark_id] = {
'type': mark_type,
'content': mark_content
}
if confirmed or locked:
logging.info(f"Confirmed or Locked: {group_id}, {para_id}, {source}, {target}")
list_data.append({
'group_id': group_id,
'para_id': para_id,
'source': source,
'target': target,
'trans_unit_id': trans_unit_id,
'confirmed': confirmed,
'locked': locked,
'tunit_metadata': tunit_metadata_dict
})
return list_data
Then, the data model for the extracted translation units is structured as follows:
list_data = [{
'group_id': group_id,
'para_id': para_id,
'source': source,
'target': target,
'trans_unit_id': trans_unit_id,
'confirmed': confirmed,
'locked': locked,
'tunit_metadata': tunit_metadata_dict
},
]You may notice that why tunit_metadata is important, it is used to store additional information about the translation unit, such as formatting tags, placeholders, or other metadata that may be relevant for the translation process. This metadata can help translators understand the context and requirements for translating specific segments:
<m:tunit-metadata>
<m:mark id="1">
<m:type>code</m:type>
<m:content>[color=#1f8a34]</m:content>
</m:mark>
<m:mark id="2">
<m:type>code</m:type>
<m:content>[/color]</m:content>
</m:mark>
<m:tunit-metadata>3. Translation Memory (TM)
When a Translation Management System (TMS) is undergoing a certain project which containing pairs of source and translated records, that is good to leverage past work into one more step processing, as there are a good knowledge for LLM to learning instead of translating from scratch with no provided context. The TM could be extracted from current MXLIFF, or sourced from various formats within the TMS.
4. Term Base (TB)
In many cases, existing term bases are provided. However, sometimes employees receive only a raw list containing original names, geographic locations, event titles, attributes, and similar elements:
source,destination
孙鲁班,Sun Luban
孙策,Sun Ce
许攸,Xu You
陈宫,Chen Gong
冲城车,Battering Ram
普通兵种,Standard Troop TypeThere are several ways to handle translation in such cases. You can use traditional tools like Google Translate or Bing Translator. Alternatively, modern approaches using large language models (LLMs) like GPT-4o offer more flexible and context-aware options. If you choose to use an LLM, consider formatting your data as structured input and output (e.g., JSON). This approach helps maintain clarity and consistency. Learn more about structured outputs here
A input prompt could be:
Translate the following into English. Context: Chinese historical novel - Three Kingdoms.
[{
"id": 1,
"source": "孙鲁班"
},
{
"id": 2,
"source": "孙策"
}]
Output object could be like this:
[{
"id": 1,
"destination": "Sun Luban"
},
{
"id": 2,
"destination": "Sun Ce"
}]The id field is important for remapping results back to the original data. You may also use a dictionary format for easier processing:
{
"1": {
"source": "孙鲁班",
"destination": "Sun Luban"
}
}If you’re aiming for high accuracy, consider adding a validation step. For example, you can prompt the model to confirm whether the translation is correct:
Validate the following translation from Chinese to English. Context: Chinese historical novel - Three Kingdoms.
{
"1": {
"source": "孙鲁班",
"destination": "Sun Luban",
"is_correct": true,
"reason_if_incorrect": "...."
}
}
This double-checking step helps ensure that translations are both contextually accurate and linguistically sound.
5. Incremental Term Base (ITB)
Here, we bring in AI. Since each localization effort often involves unique source-target translation pairs—tailored to specific contexts, it is essential to extract domain-specific terms directly from these human-validated records. Incremental Term Base addresses to TBs are extracted from translated source-dest, untranslated source. They are not from Term Base provided in previous section and also need to be translated to fill in Full Dictionary Term Base (FDTB) in next section.
A Transformer-based model is applied to the latest content (e.g., from TM or exported files) to extract newly relevant or important terms, by doing so, the ITB helps maintain consistency, reduces redundant work, and enriches the overall term base with project-relevant terminology as it is capturing terminology that emerges organically from actual translation projects.
Using LLM to extract pair translated source-dest
Let’s say you have pairs of translated and prompting:
Extract proper names, geographic locations, historical names, slang, idioms, and culturally significant phrases from the provided translation pairs.
{
"1": {
"source": "欢迎回来,{username}!您上次驻扎在洛阳,最后一次战役是在 {last_battle_time}。",
"destination": "Welcome back, {username}! Your last stationed location was Luoyang, and your last battle took place on {last_battle_time}.",
}
}Expected output
[{
"洛阳": "Luoyang"
}]Using Keybert to extract ITB in untranslated source
It is recommended to use Keybert to extract n-gram words from source, let’s say you have:
乱世出英雄,曹操、刘备、孙权三分天下,逐鹿中原。
关羽单刀赴会,于荆州饮酒谈笑,气吞万里如虎。
赤壁之战,火烧连营,周瑜智破曹军八十万。
张飞怒吼长坂桥,喝退曹军万人,孤身守关。
诸葛亮七擒孟获,以智谋安定南中,展现王者风范。
桃园三结义,刘关张誓同生死,共创蜀汉伟业。
司马懿隐忍深谋,终掌天下,改魏为晋,开千秋基业。
东吴悍将吕蒙白衣渡江,智取荆州,令关羽饮恨。
马超怒战许褚,铁骑奔腾,枪影如龙,杀声震天。
诸葛亮临终叹息:“命运不由人,天命难违,北伐终未成。
The code for extracting looks like:
from keybert import KeyBERT
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
from stopwordsiso import stopwords
import logging
logging.basicConfig(level=logging.INFO)
# Use sentence model
def add_stopwords(lang):
stop_words = list(stopwords(lang))
return stop_words
def tokenize_zh(text):
words = jieba.lcut(text)
return words
VECTORIZER = CountVectorizer(tokenizer=tokenize_zh)
def get_model():
sentence_model = SentenceTransformer("paraphrase-multilingual-mpnet-base-v2")
kw_model = KeyBERT(model=sentence_model)
return kw_model
def extract_keywords(text_array, model, **kwargs):
keywords = model.extract_keywords(text_array, vectorizer=VECTORIZER,
diversity=0.7, **kwargs)
return keywords
def test_keybert():
input_raw = """
乱世出英雄,曹操、刘备、孙权三分天下,逐鹿中原。
关羽单刀赴会,于荆州饮酒谈笑,气吞万里如虎。
赤壁之战,火烧连营,周瑜智破曹军八十万。
张飞怒吼长坂桥,喝退曹军万人,孤身守关。
诸葛亮七擒孟获,以智谋安定南中,展现王者风范。
桃园三结义,刘关张誓同生死,共创蜀汉伟业。
司马懿隐忍深谋,终掌天下,改魏为晋,开千秋基业。
东吴悍将吕蒙白衣渡江,智取荆州,令关羽饮恨。
马超怒战许褚,铁骑奔腾,枪影如龙,杀声震天。
诸葛亮临终叹息:“命运不由人,天命难违,北伐终未成。
"""
model = get_model()
zh_stopwords = add_stopwords('zh')
keywords = extract_keywords(input_raw, model, stop_words=zh_stopwords, top_n=50, keyphrase_ngram_range=(1, 3))
print(f"Keywords: {keywords}")
Adjusting top_n and keyphrase_ngram_range increases the number of terms captured. The jieba library is essential for tokenizing Chinese words—without jieba, the following output cannot be generated.
Output
Loading model cost 1.157 seconds.
DEBUG:jieba:Loading model cost 1.157 seconds.
Prefix dict has been built successfully.
DEBUG:jieba:Prefix dict has been built successfully.
Keywords: [('蜀汉', 0.8161), ('司马懿', 0.774), ('渡江', 0.7544), ('千秋', 0.7436), ('东吴', 0.7429), ('晋', 0.7411), ('刘备', 0.7408), ('周瑜', 0.7406), ('怒战许', 0.7369), ('刘', 0.7331), ('长坂', 0.7276), ('曹操', 0.7234), ('终掌', 0.7208), ('结义', 0.7205), ('荆州', 0.7056), ('单刀赴会', 0.6966), ('曹军', 0.6922), ('诸葛亮', 0.6913), ('智破', 0.6845), ('如龙', 0.6842), ('基业', 0.6785), ('中', 0.6764), ('智谋', 0.6762), ('逐鹿中原', 0.6649), ('乱世', 0.664), ('悍将', 0.6612), ('于', 0.66), ('张飞', 0.6591), ('风范', 0.6579), ('关羽', 0.6574), ('改魏', 0.6559), ('北伐', 0.6519), ('震天', 0.6514), ('临终', 0.6492), ('叹息', 0.649), ('智取', 0.6482), ('怒吼', 0.6325), ('马超', 0.6312), ('天下', 0.6299), ('火烧', 0.6258), ('奔腾', 0.6241), ('共创', 0.619), ('孙权', 0.617), ('孟获', 0.6167), ('展现', 0.6151), ('连营', 0.6151), ('喝退', 0.611), ('人', 0.6095), ('褚', 0.6049), ('隐忍', 0.5978)]This step is not finished because you need to translate ITB to accordingly destination process like previous section. Optionally, you can use LLM to do both extract and pre-translate ITB
Using LLM to extract and pre-translate ITB
Consider the prompt:
Extract all significant names, locations, military terms, and idioms from the following text and translate them from Chinese to English. Context: Chinese historical novel - Three Kingdoms.
乱世出英雄,曹操、刘备、孙权三分天下,逐鹿中原。
关羽单刀赴会,于荆州饮酒谈笑,气吞万里如虎。
赤壁之战,火烧连营,周瑜智破曹军八十万。
张飞怒吼长坂桥,喝退曹军万人,孤身守关。
诸葛亮七擒孟获,以智谋安定南中,展现王者风范。
桃园三结义,刘关张誓同生死,共创蜀汉伟业。
司马懿隐忍深谋,终掌天下,改魏为晋,开千秋基业。
东吴悍将吕蒙白衣渡江,智取荆州,令关羽饮恨。
马超怒战许褚,铁骑奔腾,枪影如龙,杀声震天。
诸葛亮临终叹息:“命运不由人,天命难违,北伐终未成。
Result in json:
{
"诸葛亮": "Zhuge Liang",
....
}Expected Output:
{
"乱世出英雄": "Heroes arise in troubled times",
"曹操": "Cao Cao",
"刘备": "Liu Bei",
"孙权": "Sun Quan",
"三分天下": "Three Kingdoms division",
"逐鹿中原": "Competing for supremacy in Central Plains",
"关羽": "Guan Yu",
"单刀赴会": "Attending a meeting alone with a single blade",
"荆州": "Jingzhou",
"气吞万里如虎": "With a mighty presence, like a tiger dominating vast lands",
"赤壁之战": "Battle of Red Cliffs",
"火烧连营": "Burning consecutive camps",
"周瑜": "Zhou Yu",
"曹军": "Cao’s army",
"张飞": "Zhang Fei",
"长坂桥": "Changban Bridge",
"喝退曹军万人": "Roaring away ten thousand Cao soldiers",
"孤身守关": "Guarding the pass alone",
"七擒孟获": "Seven captures of Meng Huo",
"智谋安定南中": "Using strategy to pacify Southern China",
"王者风范": "Regal demeanor",
"桃园三结义": "Oath of the Peach Garden",
"刘关张": "Liu Bei, Guan Yu, Zhang Fei",
"誓同生死": "Swearing to live and die together",
"蜀汉伟业": "Great cause of Shu Han",
"司马懿": "Sima Yi",
"隐忍深谋": "Patient and deep strategist",
"终掌天下": "Ultimately ruling the realm",
"改魏为晋": "Changing Wei to Jin",
"开千秋基业": "Establishing a lasting foundation",
"东吴": "Eastern Wu",
"吕蒙": "Lü Meng",
"白衣渡江": "Crossing the river in plain clothes",
"智取荆州": "Strategically capturing Jingzhou",
"令关羽饮恨": "Making Guan Yu bitterly regret",
"马超": "Ma Chao",
"怒战许褚": "Fiercely fighting Xu Chu",
"许褚": "Xu Chu",
"铁骑奔腾": "Galloping iron cavalry",
"枪影如龙": "Lance shadows like dragons",
"杀声震天": "Battle cries shaking the sky",
"命运不由人": "Fate is not determined by man",
"天命难违": "Heaven’s will is hard to defy",
"北伐终未成": "Northern expedition ultimately failed"
}
6. Full Dictionary Term Base (FDTB)
We merge the existing TB and the newly generated ITB to form the Full Dictionary Term Base (FDTB) - A comprehensive version of the TB that includes all validated and approved terms. This enriched dictionary captures both static and dynamic terminology and forms a critical input for validation and LLM-enhanced review.
Finally, it will still look like after merging via key dictionary:
{
"乱世出英雄": "Heroes arise in troubled times",
"曹操": "Cao Cao",
"刘备": "Liu Bei",
"孙权": "Sun Quan",
.....
}
But we will transform a bit to list based for easier processing, :
dictionary_list = [
{"source": "乱世出英雄", "target_human": "Heroes arise in troubled times"},
{"source": "曹操", "target_human": "Cao Cao"},
{"source": "刘备", "target_human": "Liu Bei"},
{"source": "孙权", "target_human": "Sun Quan"},
# ...
]Wrapping up
At this stage in the pipeline, we’ve successfully gathered translation memories, extracted terminology, and combined both static and dynamic sources to form the Full Dictionary Term Base (FDTB). This consolidated glossary is critical for ensuring that translations remain consistent, context-aware, and aligned with evolving project needs.
But building the FDTB is just the beginning. In the next stage, we move from preparation to action — parsing actual translation files and applying our term base to evaluate and enhance translation quality.
Series LLM-Powered Localization Pipeline:

Table of Contents
- 1. Key Terms & Abbreviations
- 2. Traditional Localization
- 3. LLM-Powered approach to build Full Dictionary Term Base (FDTB)