In the previous post, we explored how to use LLMs to generate translations in a localization pipeline. Which applied GPT-4o to genererate Full Dictionary Term Base (FDTB). We will continue to build on that foundation and introduce a more structured approach to localization.
LLM-Powered to translate with rules
Let’s take a look at the localization pipeline we are going to build:
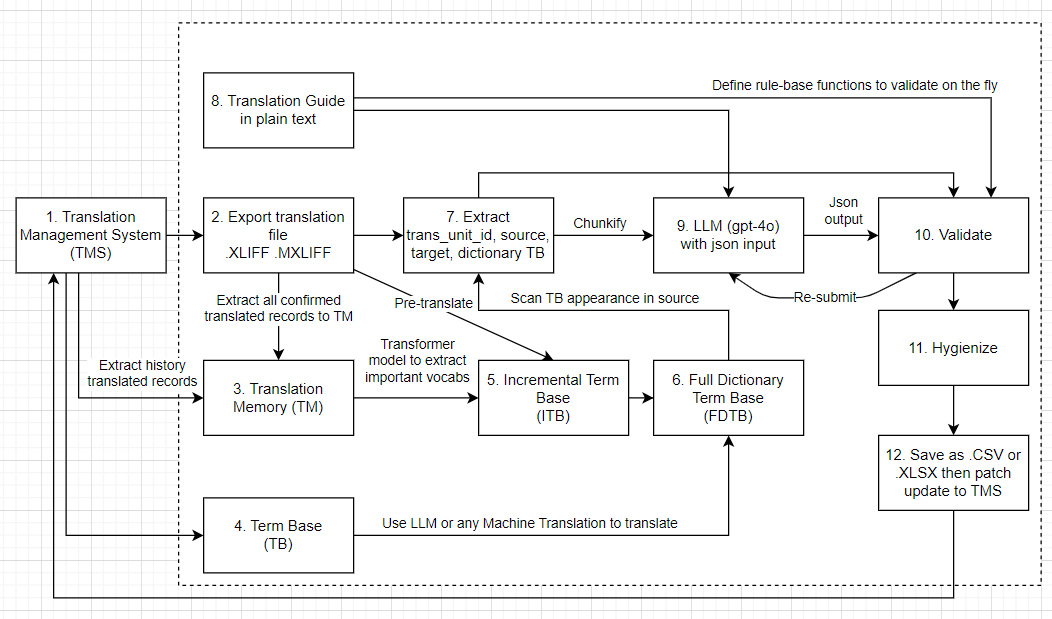
7. Extract Data Level 2, Dictionary List and Chunkify Submit Data
Transforming Dictionary and Translation Data
From step 6, we already had a Full Dictionary Term Base (FDTB) dictionary that contains all the terms and their translations.
dictionary = {
"乱世出英雄-曹操": "Heroes arise in troubled times - Cao Cao",
"英雄": "Heroes",
"曹操": "Cao Cao",
"刘备": "Liu Bei",
"孙权": "Sun Quan",
.....
}
And converted to dictionary list format:
dictionary_list = [
{"source": "乱世出英雄", "target_human": "Heroes arise in troubled times"},
{"source": "曹操", "target_human": "Cao Cao"},
{"source": "刘备", "target_human": "Liu Bei"},
{"source": "孙权", "target_human": "Sun Quan"},
# ...
]I marked the target_human field to indicate that this is the human validated of the term.
And step 2, we have exported the translation file from the Translation Management System (TMS) in a format like XLIFF or MXLIFF, we called Data Level 1.
Here is a sample of what data_level_1 might look like:
data_level_1 = [
{
'group_id': 'group_1',
'para_id': 'para_1',
'source': '乱世出{1}英雄{2}',
'target': 'Heroes arise in troubled times',
'trans_unit_id': 'trans_unit_id_1',
'confirmed': True,
'locked': False,
'tunit_metadata': {
"1": {
"type": "code",
"content": "[color=#1f8a34]"
},
"2": {
"type": "code",
"content": "[/color]"
}
}
},
{
'group_id': 'group_1',
'para_id': 'para_2',
'source': '{1}曹操{2}',
'target': 'Cao Cao',
'trans_unit_id': 'trans_unit_id_2',
'confirmed': True,
'locked': False,
'tunit_metadata': {
"1": {
"type": "code",
"content": "[b]"
},
"2": {
"type": "code",
"content": "[/b]"
}
}
}
]We will process to Data Level 2 by build_data_level_2(), the purpose of this code is to process and normalize translation unit data exported from a Translation Management System (TMS). It converts a list of translation units into a dict type keyed by trans_unit_id, parses and cleans up any embedded metadata (especially unescaping HTML entities in text fields), and prepares the data in a structured format suitable for further processing.
def build_data_level_2(data_level_1):
dct = {}
for item in data_level_1:
dct[item['trans_unit_id']] = item
if 'tunit_metadata' in item and type(item["tunit_metadata"]) == str:
metadata_text = item["tunit_metadata"].replace('\"', '\\"').replace('\'','\"')
item["tunit_metadata"] = json.loads(metadata_text)
item["tunit_metadata"] = normalize_tunit(item["tunit_metadata"])
return dct
def normalize_tunit(tunit_metadata):
for k, v in tunit_metadata.items():
tunit_metadata[k]['content'] = unescape_multiple(tunit_metadata[k]['content'])
return tunit_metadata
import html
def unescape_multiple(text):
while True:
new_text = html.unescape(text)
if new_text == text: # No change means it's fully unescaped
break
text = new_text
return text
Imagine the data_level_2 is structured like this:
data_level_2 = {
'trans_unit_id_1': {
'group_id': 'group_1',
'para_id': 'para_1',
'source': '乱世出{1}英雄{2}',
'target': 'Heroes arise in troubled times', #This is not translated yet
'trans_unit_id': 'trans_unit_id_1',
'confirmed': True,
'locked': False,
'tunit_metadata': {
"1": {
"type": "code",
"content": "[color=#1f8a34]"
},
"2": {
"type": "code",
"content": "[/color]"
}
}
},
}Transforming Submit Data for LLM Translation
Next step, we will process to Submit Data where we only submit necessary information to LLM. The build_submit_data() function processes the data_level_2 dictionary, filtering out translation units that have already been translated (i.e., those with a non-null target). It constructs a list of dictionaries, each containing the trans_unit_id, source text, and any relevant entries from the term base (dictionary) that match the source text. This prepares the data for submission to an LLM for translation.
import logging
logging.basicConfig(level=logging.INFO)
def build_submit_data(data_level_2, dictionary_list=None):
logging.info(f'Number of rows: {len(data_dict)}')
submit_data = []
for k, val in data_level_2.items():
if val['target'] is None:
source = val['source']
submit_row = {
'trans_unit_id': val['trans_unit_id'],
'source': source,
}
if dictionary_list is not None:
found_translated = search_dictionary(source, dictionary_list, number_of_results=-1)
submit_row['dictionary'] = found_translated
submit_data.append(submit_row)
logging.info(f'Number of rows to be translated: {len(submit_data)}/{len(data_level_2)}')
return submit_data
def search_dictionary(text, dictionary_list, number_of_results=3):
# if any source in text, return target
found_items = []
for item in dictionary_list:
if item['source'] in text:
# to prevent
if item['target_human'] is not None:
found_items.append({
'source': item['source'],
'target': item['target_human']
})
if number_of_results == -1:
continue
if len(found_items) >= number_of_results:
break
return found_itemsFinally, each translation unit is structured as follows:
submit_data = [{
"trans_unit_id": "trans_unit_id_1",
"source": "乱世出{1}英雄{2}-",
"target": "Heroes arise in troubled times",
"dictionary": {
"乱世出英雄": "Heroes arise in troubled times",
"英雄": "Heroes",
},
}]Enhancing Dictionary Search with NLP
The search_dictionary() function currently uses simple string matching to find dictionary terms in the source text. While this approach works for exact matches, it can miss variations, synonyms, or contextually similar terms.
To make term recognition more robust, we could enhance this function with various NLP techniques:
Embeddings and Cosine Similarity
- Convert terms and source text to vector representations
- Calculate similarity scores between vectors
- Match terms with similarity above a threshold
- Better captures semantic relationships between terms
Fuzzy Matching
- Use Levenshtein distance or other edit distance metrics
- Find terms that are similar but not identical
- Set appropriate threshold to avoid false positives
- Helps with minor spelling variations or inflections
Contextual Matching
- Consider surrounding words when matching terms
- Use sliding window approaches to capture phrases
- Weight matches based on contextual relevance
Language-Specific Processing
- Apply stemming or lemmatization for morphologically rich languages
- Consider word boundaries and segmentation for languages like Chinese
- Implement custom tokenization strategies when needed
These approaches can be combined and weighted based on the specific language pair and translation requirements, dramatically improving the quality of dictionary term matching.
Chunking Submit Data and Iterative Correction
When working with large datasets, especially in translation tasks, it is crucial to manage the data efficiently. The submit_data we built in the previous step is a list of dictionaries, each representing a translation unit that needs to be processed by an LLM. Thus, submit_data is divided into manageable “chunks”, each chunk contains a subset of translation units, along with their associated term base entries and context. Chunking enables parallel processing and helps LLMs handle input size limitations. At the moment implemented this code, GPT-4o input tokens are 128k tokens, which is quite large - nowadays June-2025, GPT-4.1 replaces base model GPT-4o with 1M context window, but it is still a good practice to chunk the data for better performance because its hallucination rate is still high, and it is not guaranteed that all translations will be correct.
def chunkify(submit_data, chunk_size):
chunks = []
for i in range(0, len(submit_data), chunk_size):
chunks.append(submit_data[i:i+chunk_size])
return chunksTo use:
chunk_size = 10 # Define your chunk size
chunks = chunkify(submit_data, chunk_size)
total_chunks = len(chunks)
for index, chunk in enumerate(chunks):
logging.info(f'Processing chunk {index + 1}/{total_chunks} with {len(chunk)} items')
# Process each chunk with the LLM
chunk_dict = {i['trans_unit_id']: i for i in chunk}
# Send chunk_dict to the LLM for translation
Output chunk_dict will look like this:
chunk_dict = {
"trans_unit_id_1":{
"trans_unit_id": "trans_unit_id_1",
"source": "乱世出{1}英雄{2}-",
"target": "Heroes arise in troubled times",
"dictionary": {
"乱世出英雄": "Heroes arise in troubled times",
"英雄": "Heroes",
},
}
}
Why we did not build submit_data as dict type from the beginning? Because it is easier to process and manipulate data in list loopingly, especially when you need to filter out items or apply transformations. However, once you have the chunk, converting it to a dict type allows for faster lookups and mappings, mainly for 2 purposes:
- To search and map
trans_unit_idquickly after the LLM returns the results with BigO(1) complexity. - These are no 100% guarantee that all returned translations will be correct and be translated
The second point is most challenge I have met, to overcome this, each chunk is having 3 mechanisms:
- Keep looping until all items in the chunk are translated, with non-translated items being resubmitted to the LLM.
- Keep validation functions that check the output of the LLM against the rules defined in the translation guide, if not valid, resubmit the chunk to the LLM.
- For each error or issue detected, log it and provide feedback to the LLM for correction. This iterative process helps refine translations and improve quality over time.
Uncompleted code for the chunk processing loop:
data_level_2 = build_data_level_2(data_level_1)
NUMBER_OF_TRIES_LIMIT = 10
for index, chunk in enumerate(chunks):
number_of_tries = 0
logging.info(f'Processing chunk {index + 1}/{total_chunks} with {len(chunk)} items')
focus_prompt = ''
is_new_chunk = True
chunk_dict = {}
while True:
try:
if is_new_chunk:
chunk_dict = {i['trans_unit_id']: i for i in chunk}
if not chunk_dict:
logging.info(f'No more items in chunk {index}, moving to next chunk')
break # No more items to process in this chunk
# Send chunk_dict to the LLM for translation
llm_response = post_to_llm(chunk_dict, translation_guide, focus_prompt....)
# Validate the LLM response for each item in the response
for translated_item in llm_response:
target = translated_item.get('target', None)
item_data_level_2 = data_level_2.get(translated_item['trans_unit_id'], None)
validation_result = validate(translated_item, item_data_level_2)
# If any invalid, add to focus prompt for next iteration
if not validation_result['is_valid']:
focus_prompt += validation_result['invalid_reason']
# Invalid reason example: f"When translating \"{target}\", the following Chinese words were detected: {xxxxx}. Please translate these words manually and re-run the chunk."
raise Exception(f"Invalid {translated_item['trans_unit_id']}: to {target}, invalid reason: {validation_result['invalid_reason']}")
# And other validation rules can be added here
# if valid, update the chunk_dict like this
del chunk_dict[translated_item['trans_unit_id']]
item_data_level_2['target'] = target
is_new_chunk = False
except Exception as e:
logging.info(f"Error processing {file_name} chunk {index}: {e}")
number_of_tries += 1
logging.info(f"Number of tries: {number_of_tries} for {file_name} chunk {index}")
if number_of_tries >= NUMBER_OF_TRIES_LIMIT:
logging.error(f"Number of tries exceeded {NUMBER_OF_TRIES_LIMIT}, stop program")The above code snippet more advanced to serve:
- Remove out already translated items.
- Validate each translation using a validate() function.
- If a translation is missing or invalid (e.g., untranslated Chinese words remain), it logs the issue, updates the prompt for the LLM, and retries the chunk, making its iterative correction. The
focus_promptis built up with invalid reasons to help the LLM understand what went wrong and how to correct it in the next iteration, we will talk about this in next post. - Retries are limited by NUMBER_OF_TRIES_LIMIT to avoid infinite loops.
- Update final
data_level_2with the translated items, so that it can be used as the final output for the localization pipeline.
We will go deep dive the post_to_llm() and validate() functions in the Step 9 and Step 10. Next section Step 8, we will build a translation guide that will be fed to the LLM to ensure it follows the rules and guidelines for translation.
8. Translation Guide
A translation guide is generated in plain text, providing translators and reviewers with clear instructions, style guidelines, and any project-specific rules. This guide can include:
- Glossary/term base usage
- Style and tone requirements
- Formatting and placeholder rules
- Examples of correct and incorrect translations
This guide helps ensure consistency and quality throughout the translation process. You will embed this guide in the prompt sent to the LLM, ensuring that it has all the necessary context to generate or review translations effectively.
For example, the guide for Chinese to Vietnamese translation might look like this. Notice that the len(input_object) is a rule that you can use to validate the output of the LLM. It means that the number of responses must match the number of input items. This is useful to ensure that the LLM does not generate extra or missing translations:
Translation Guide for Chinese to Vietnamese
BEAR IN MIND:
- Language: Translate all content into **full Vietnamese**. Use pure Vietnamese for general terms; use Sino-Vietnamese only for proper nouns or names.
- Technical:
- Preserve all special characters and formatting exactly as in the source.
- Maintain line breaks and formatting, e.g., if a line ends with `\` and the next starts with `n`, keep this structure.
- Keep placeholders such as `{{1}}`, `{{2}}`, etc., unchanged.
- Do not alter or remove symbols like ~, !, @, #, $, %, ^, &, *, (, ), _, +, =, [, ], |, \, :, ;, ", ', <, >, ?, /.
- Do not add extra punctuation; match the ending punctuation (e.g., period) to the source.
- The number of responses must match the number of input items (`len(input_object)`).
- If the `dictionary` key is present, use it to translate relevant terms.Or guide for Chinese to English translation might look like this:
Translation Guide for Chinese to English
BEAR IN MIND:
- Language: Translate all content into **full English**. Use pure English for general terms; use loanwords only for proper nouns or names.Another example for Japanese to English translation might look like this:
Translation Guide for Japanese to English Game Localization
BEAR IN MIND:
- Language:
- Translate all content into natural, idiomatic English
- Preserve gaming terminology appropriate for the target audience
- Adapt honorifics and politeness levels appropriately for English players
- Maintain the tone and style of characters (casual, formal, etc.)
- Technical:
- Respect character limits: Japanese text is often more compact than English
- Preserve all variables like {0}, {1}, {PlayerName}, etc.
- Maintain HTML/BBCode tags: <b>bold</b>, <i>italic</i>, [color=#FF0000]red text[/color]
- Keep UI markers intact: [BUTTON_A], [MENU], etc.
- Handle gender variables properly if present: {his/her}, {he/she}
- Preserve line break markers (\n, <br>, etc.)
- Maintain pluralization markers for dynamic text: "Found {0} item(s)"
- Game-Specific:
- Use established translations for game mechanics, items, and character names
- Adapt jokes, puns, and cultural references to maintain player experience
- Consider text expansion limits for UI elements (buttons, menus, tooltips)
- Maintain numbering conventions for damage, stats, percentages
- Use appropriate capitalization for game terms (Skills, Items, Locations)
- Keep spacing consistent for text that appears in dialogue boxes
- Cultural:
- Adapt cultural references that wouldn't be understood by target audience
- Maintain age-appropriate content per regional rating standards
- Consider platform-specific terminology (controller buttons, actions)
- Adapt onomatopoeia and sound effects to English conventions
- Response Format:
- The number of responses must match the number of input items (`len(input_object)`)
- For each translation unit, include both source text and target text
- Flag any uncertain translations with [CHECK] markerIn overrall, the guide should be clear, concise, and tailored to the specific translation task. It should help translators and reviewers understand the expectations and requirements for the translation, ensuring high-quality output.
From the guide, you also need to create validation functions that will be used in 10 to validate the output of the LLM. These functions will check if the output adheres to the rules defined in the guide. For example, you can create a function that checks if the number of responses matches the number of input items, or if the placeholders are used correctly.
Wrapping Up
In this post, we have transformed to data_level_2 for storing final output and submit_data for submitting LLM. The submit_data attached the Full Dictionary Term Base (FDTB) dictionary_list for relevant terms. We have also chunked the data for efficient processing and built a structured approach to handle translations using LLMs. Before to LLM step, we introduced the translation guide, which provides clear instructions and rules for the LLM to follow during translation.
Series LLM-Powered Localization Pipeline:
