This article describes the final “hygiene” step in an LLM-powered localization pipeline, focusing on programmatically cleaning and validating translated records. It covers removing unnecessary characters, normalizing Unicode, converting punctuation, detecting mismatches and unwanted Chinese characters, adjusting variable spacing, and ensuring all placeholders are present—ensuring translation quality before saving or patching to a TMS.
Post-processing Translated Records
Bravo, we are almost done with our localization pipeline! In the previous post, we have successfully validated the translated records by iteratively checking the translation quality and resubmitting the records to the LLM. Now we will do the final step, which is hygiene these records and remove any unnecessary information.
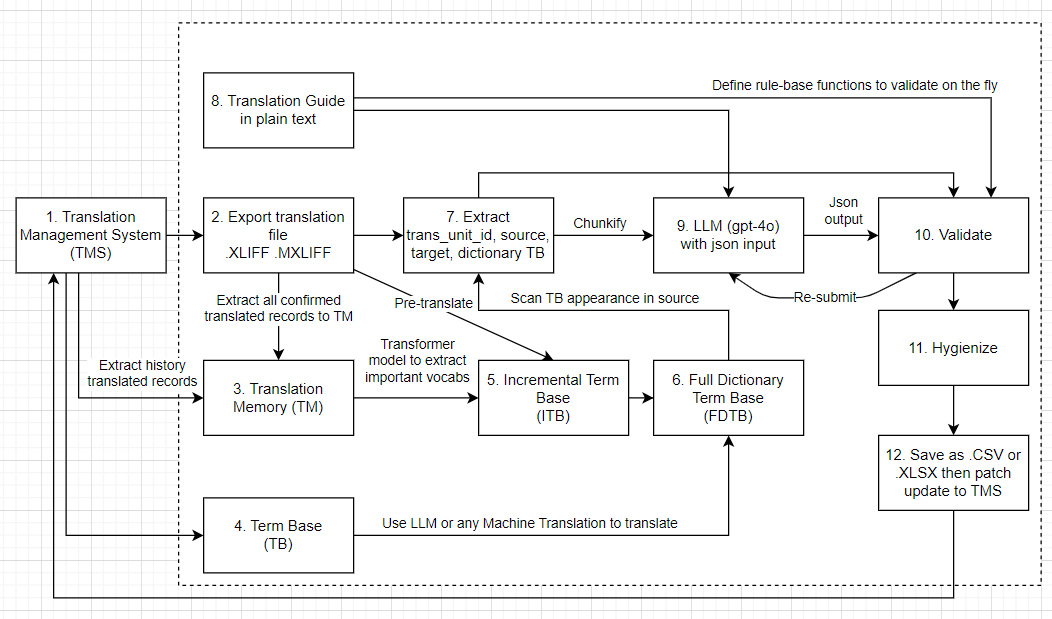
11. What is Hygiene?
It is frequent that the LLM will generate some unnecessary information in the translated records, such as:
- Redundant spaces, line breaks, punctuation, etc.
- Chinese characters like quotes, when translating to alphabetic languages, there would need to be some replacements.
- Unnecessary HTML tags, such as
<p>,<br>, etc. - Extra spaces among placeholder code, “{1} This is a test {2}”, which should be “{1}This is a test{2}” if {1} and {2} are color [color], [/color] tags respectively.
These hygiene processes no need to submit to LLM, obviously it is about programmatic string manipulation.
Let’s take a look at the data_level_2 dict type we have in the few previous posts:
data_level_2 = {
'trans_unit_id_1': {
'group_id': 'group_1',
'para_id': 'para_1',
'source': '乱世出{1}英雄{2}',
'target': '{1} Heroes {2} arise in troubled times',
'trans_unit_id': 'trans_unit_id_1',
'confirmed': True,
'locked': False,
'tunit_metadata': {
"1": {
"type": "code",
"content": "[color=#1f8a34]"
},
"2": {
"type": "code",
"content": "[/color]"
}
}
},
...
}We will hygiene flow for the target field of each record in this dict with the template function like this, note that you may perform some of them sequentially in some cases:
def _process_hygiene_function_flow(data_dict, check_column='target', to_column='target', fix_callback=None):
for key, item in data_dict.items():
target = item.get(check_column, None)
if target is None:
continue
# Perform hygiene operations on the target text
converted = hygiene_function(target)
item[to_column] = converted
if target == converted:
continue
logging.info(f"Hygiene conversion to column {to_column} [{key}] {target} -> {converted}")
fix_callback(True) if fix_callback else None
return data_dictWhat does this template hygiene function do?
- Iterates through each record in your translation dictionary (data_dict).
- Checks for the target text (or any specified column) in each record.
- Applies a
hygiene_function()to clean up the text—removing unwanted spaces, fixing punctuation, or stripping out unnecessary HTML tags. - Updates the record with the cleaned text, it could be the same column or a different one
to_columnif for review purposes. - Logs the change if any modification was made, making it easy to track what was cleaned.
- Optionally triggers a callback if you want to perform additional actions after a fix.
Hygiene composed form
In the Validation step, I have used the unicodedata.normalize() function to convert the text to a composed form, if you did not apply that, you can use the following code to hygiene the composed form of the text.
import unicodedata
def normalize_text(text):
# Normalize to NFC (composed form)
return unicodedata.normalize('NFC', text).strip()
def _process_composed_form_flow(data_dict, check_column='target', to_column='target', fix_callback=None):
for key, item in data_dict.items():
target = item.get(check_column, None)
if target is None:
continue
converted = normalize_text(target)
item[to_column] = converted
if target == converted:
continue
logging.info(f"Composed form conversion to column {to_column} [{key}] {target} -> {converted}")
fix_callback(True) if fix_callback else None
return data_dictWhy it is important?
In Unicode, characters can often be represented in multiple ways. The two most common normalization forms are:
- NFC (Normalization Form C, Composed): Characters are composed into a single code point where possible.
- NFD (Normalization Form D, Decomposed): Characters are split into base characters and combining marks.
Example: The character “é”
- Single code point (composed, NFC):
- Unicode: U+00E9
- Python: ‘é’
- Decomposed (NFD):
- Unicode: U+0065 (e) + U+0301 (combining acute accent)
- Python: ‘e\u0301’
import unicodedata
s1 = 'é' # Composed form (NFC)
s2 = 'e\u0301' # Decomposed form (NFD)
print(s1 == s2) # False
print(unicodedata.normalize('NFC', s2) == s1) # True
print(unicodedata.normalize('NFD', s1) == s2) # TrueYou may improve it further in your own language basically.
Convert punctuation
Chinese is an interesting language, it has its own punctuation marks, such as , (comma), 。 (period), ! (exclamation mark), etc. When translating to alphabetic languages, we need to convert these punctuation marks to their English counterparts, such as ,, ., !, etc.
# Expanded dictionary for Chinese and full-width punctuation to English equivalents
punctuation_map = {
"·": "-", # Middle dot
"。": ".", # Full stop
",": ",", # Comma
"、": ",", # Enumeration comma (same as comma)
";": ";", # Semicolon
":": ":", # Colon
"?": "?", # Question mark
"!": "!", # Exclamation mark
"。": ".", # Japanese full stop (。)
""": "\"", # Quotation mark (full-width)
"#": "#", # Hash (full-width)
"$": "$", # Dollar sign (full-width)
"%": "%", # Percent sign (full-width)
"&": "&", # Ampersand (full-width)
"'": "'", # Apostrophe (full-width)
"(": "(", # Parentheses (full-width)
")": ")", # Parentheses (full-width)
"*": "*", # Asterisk (full-width)
"+": "+", # Plus sign (full-width)
",": ",", # Comma (full-width)
"-": "-", # Minus (full-width)
"/": "/", # Slash (full-width)
":": ":", # Colon (full-width)
";": ";", # Semicolon (full-width)
"<": "<", # Less than sign (full-width)
"=": "=", # Equals sign (full-width)
">": ">", # Greater than sign (full-width)
"@": "@", # At sign (full-width)
"[": "[", # Left square bracket (full-width)
"\": "\\", # Backslash (full-width)
"]": "]", # Right square bracket (full-width)
"^": "^", # Caret (full-width)
"_": "_", # Underscore (full-width)
"`": "`", # Backtick (full-width)
"{": "{", # Left curly brace (full-width)
"|": "|", # Pipe (full-width)
"}": "}", # Right curly brace (full-width)
"~": "~", # Tilde (full-width)
"⦅": "[", # Open corner bracket (full-width)
"⦆": "]", # Close corner bracket (full-width)
"「": "「", # Opening corner bracket (Chinese quotation)
"」": "」", # Closing corner bracket (Chinese quotation)
"、": ",", # Japanese comma (。)
"、": ",", # Japanese enumeration comma
"〃": "\"", # Ditto mark (used to repeat a phrase)
"》": "\"", # Chinese right angle quotation mark
"《": "\"", # Chinese left angle quotation mark
"「": "“", # Left Chinese quotation mark
"」": "”", # Right Chinese quotation mark
"『": "‘", # Left corner quotation mark
"』": "’", # Right corner quotation mark
"【": "[", # Left square bracket (Chinese)
"】": "]", # Right square bracket (Chinese)
"〔": "[", # Left curly bracket (Chinese)
"〕": "]", # Right curly bracket (Chinese)
"〖": "[", # Left double square bracket
"〗": "]", # Right double square bracket
"〘": "[", # Left round bracket (Chinese)
"〙": "]", # Right round bracket (Chinese)
"〚": "[", # Left parenthesis (Chinese)
"〛": "]", # Right parenthesis (Chinese)
"〜": "~", # Full-width tilde (similar to ~)
"〝": "\"", # Left double quotation mark (Chinese)
"〞": "\"", # Right double quotation mark (Chinese)
"〟": "\"", # Quotation marks
"〰": "-", # Wavy dash
"〾": "~", # Wavy tilde
"〿": "~", # Full-width tilde
"–": "-", # En dash (similar to English dash)
"—": "-", # Em dash (double dash)
"‘": "'", # Left single quotation mark (English)
"’": "'", # Right single quotation mark (English)
"‛": "'", # Reversed single quotation mark
"“": "\"", # Left double quotation mark
"”": "\"", # Right double quotation mark
"„": "\"", # Low double quotation mark
"‟": "\"", # Reversed low double quotation mark
"…": "...", # Ellipsis
"‧": ".", # Dotted symbol, similar to period
"﹏": "_", # Low line or underscore
"»": ">", # Right angle quotation mark
"«": "<", # Left angle quotation mark
"‹": "<", # Left angle bracket
"›": ">", # Right angle bracket
"〈": "<", # Left angle bracket (Chinese)
"〉": ">", # Right angle bracket (Chinese)
}
def convert_punctuation(text):
# Replace each Chinese and full-width punctuation character with its English equivalent
for ch, replacement in punctuation_map.items():
text = text.replace(ch, replacement)
return textApplying this to our data_level_2 dict, we can use the following code:
def _process_target_punct_flow(data_dict, check_column='target', to_column='target', fix_callback=None):
for key, item in data_dict.items():
target = item.get(check_column, None)
if target is None:
continue
converted = convert_punctuation(target)
item[to_column] = converted
if target == converted:
continue
logging.info(f"Punctuation conversion to column {to_column} [{key}] {target} -> {converted}")
fix_callback(True) if fix_callback else None
return data_dictDetect punctuation mismatches
Why we need to detect punctuation mismatches? Because the translation may have some punctuation mismatches between the source and target text, for example, the source text has a comma , but the target text has a period ., or the source text has seven punctuation marks but the target text has only six. This can lead to confusion and misinterpretation of the text, especially in languages that rely heavily on punctuation to convey meaning.
For example of good punctuation ordering:
Source: “乱世出英雄,三国演义!” => [",", "!"]
- Target (before conversion): “Heroes arise in troubled times, Three Kingdoms !” =>
[",", "!"] - Target (after conversion): “Heroes arise in troubled times, Three Kingdoms!” =>
[",", "!"]are correct because both source and target texts have the same punctuation marks in the same order, after conversion. - Target (no coversion if LLM automatically converted punctuation): “Heroes arise in troubled times, Three Kingdoms!” =>
[",", "!"]
Bad punctuation ordering:
Source: “乱世出英雄,三国演义!” => [",", "!"]
- Target (before conversion): “Heroes arise in troubled times, Three Kingdoms。” =>
[",", "。"] - Target (after conversion): “Heroes arise in troubled times, Three Kingdoms.” =>
[",", "."] - Target (no coversion if LLM automatically converted punctuation): “Heroes arise in troubled times, Three Kingdoms.” =>
[",", "."]are incorrect because the source text has a!it must be!in the target text, not.
We will use not char.isalnum() to extract all the punctuation marks from both source and target and compare them as array comparison
source = "Hello, world! 123 (test)."
punctuation = [char for char in source if not char.isalnum() and char != ' ']
print(punctuation) # Output: [',', '!', '(', ')', '.']In my case I only need to detect, not process hygiene, so if you have time you can also process to match the target punctuation marks.
def is_punctuation_equal(source, target, with_source_converted=True):
if with_source_converted:
source = convert_punctuation(source)
source_punctuation = [char for char in source if not char.isalnum() and char != ' ']
target_punctuation = [char for char in target if not char.isalnum() and char != ' ']
is_equal = source_punctuation == target_punctuation
return is_equal, source_punctuation, target_punctuation
## This function should run after process_target_punct_flow
def _detect_punctuation_mismatch_flow(data_dict, check_source_column='source', check_target_column='target', detect_callback=None):
for key, item in data_dict.items():
target = item.get(check_target_column, None)
source = item.get(check_source_column, None)
if target is None or source is None:
continue
is_equal, source_punctuation, target_punctuation = is_punctuation_equal(source, target)
if is_equal:
continue
logging.info(f"Punctuation mismatch detected [{key}] {source} -> {target} | {source_punctuation} -> {target_punctuation}")
item['punctuation_mismatch'] = f"{source_punctuation} -> {target_punctuation}"
detect_callback(True) if detect_callback else None
return data_dict
Detect chinese characters
Similar to how the hygiene composed form can be converted directly without notice, we have two options for handling Chinese characters: we can either resubmit the records to the LLM for retranslation, or simply detect their presence in the target text. If Chinese characters are detected, they can be translated later using an alternative machine translation service if available.
import re
CHINESE_WORD_PATTERN = re.compile(r'[\u3400-\u4dbf\u4e00-\u9fff\uf900-\ufaff]+')
def detect_chinese_with_regex(text):
# Define a regex pattern to match Chinese characters
# Find all Chinese words in the text
chinese_words = CHINESE_WORD_PATTERN.findall(text)
return chinese_words
def _detect_chinese_flow(data_dict, check_column='target', detect_callback=None):
for key, item in data_dict.items():
target = item.get(check_column, None)
if target is None:
continue
words = detect_chinese_with_regex(target)
if len(words) == 0:
continue
logging.info(f"Chinese words detected [{key}] {target} -> {words}")
detect_callback(True) if detect_callback else None
return data_dictProcess variable spaces
We may have some variables in the target text, such as {1}, {2}, etc., which are used to represent some code or color tags. We need to ensure that there are no extra spaces between these variables and the surrounding text. For example, if we have a target text like {1} This is a test {2}, we need to convert it to {1}This is a test{2} if {1} and {2} are color tags. But if they are naming variables, we can keep the spaces, for example, Our here {1} defeated {2} the enemy, we can keep the spaces as {1} defeated {2}. In short, we will base on the metadata of the translation unit to determine how to handle these variables.
def remove_color(text):
text = re.sub(r'\[color=#[0-9a-fA-F]+\]', '', text)
text = re.sub(r'\[/color\]', '', text)
return text
def replace_variable(text, metadata):
for i in metadata:
var = i
if var in text:
content = metadata[i]['content']
if 'color=' in content or '<#' in content:
text = text.replace(var, content)
elif '/color' in content:
text = text.replace(var, content)
else:
continue
return text
def adjust_space_between_variables(text, tunit_metadata):
tunit_metadata = {k: {'content': v['content']} for k, v in tunit_metadata.items()}
metadata = {"{" + k + "}": v for k, v in tunit_metadata.items()}
queue = []
index = 0
while index < len(text):
if text[index] == '{':
var_start = index
# find next '}'
while index < len(text) and text[index] != '}':
index += 1
index += 1
queue.append(text[var_start:index])
elif text[index] in [',', '.', '!', '?', ':', ';', '[', ']', '(', ')', '"']:
queue.append(text[index])
index += 1
elif text[index] == ' ':
index += 1
elif text[index].isalnum():
word_start = index
while index < len(text) and (text[index].isalnum() or text[index] == "%"):
index += 1
queue.append(text[word_start:index])
else:
queue.append(text[index])
index+=1
merge_queue = []
stack = []
break_line_index = []
for index, token in enumerate(queue):
if index == 0:
merge_queue.append(token)
continue
previous_token = queue[index-1]
if token in metadata and previous_token not in metadata:
content = metadata[token]['content']
if 'color=' in content or '<#' in content:
merge_queue.append(token)
elif '/color' in content:
merge_queue[-1] += token
else:
if merge_queue[-1] not in content:
if merge_queue[-1] in ['[', '(', '"']:
merge_queue[-1] += token
else:
merge_queue.append(token)
if content == '\\n': break_line_index.append(token)
else:
merge_queue[-1] += token
elif token in metadata and previous_token in metadata:
content = metadata[token]['content']
if 'color=' in content or '<#' in content:
merge_queue[-1] += token
elif '/color' in content:
merge_queue[-1] += token
else:
merge_queue[-1] += token
elif token == '"':
if stack and stack[-1] == '"':
merge_queue[-1] += token
stack.pop()
else:
merge_queue.append(token)
stack.append(token)
elif token in ['[', '(']:
merge_queue.append(token)
elif token in [']', ')']:
merge_queue[-1] += token
elif token in [',', '.', '!', '?', ':', ';']:
merge_queue[-1] += token
elif previous_token in metadata:
content = metadata[previous_token]['content']
if 'color=' in content or '<#' in content:
merge_queue[-1] += token
elif '/color' in content:
merge_queue.append(token)
else:
merge_queue.append(token)
else:
merge_queue.append(token)
# logging.info(f"Queue: {queue}")
# logging.info(f"Merge queue: {merge_queue}")
text = ' '.join(merge_queue)
for i in break_line_index:
text = text.replace(f' {i} ', i)
hidden_color_text = remove_color(replace_variable(text, metadata))
return text, hidden_color_text
def _process_variable_space_flow(data_dict, check_column='target', fix_callback=None):
for key, item in data_dict.items():
target = item.get(check_column, None)
if target is None:
continue
tunit_dict = item.get('tunit_metadata', None)
if tunit_dict is None or len(tunit_dict) == 0:
continue
suggest_target, hidden_color_target = adjust_space_between_variables(target, tunit_dict)
if target == suggest_target:
continue
logging.info(f"Variable detected [{key}] {target} -> {suggest_target}")
fix_callback(True) if fix_callback else None
item['suggest_target'] = suggest_target
item['hidden_color_target'] = hidden_color_target
return data_dictThe function adjust_space_between_variables(text, tunit_metadata) is designed to clean up and standardize the spacing between variable placeholders (such as {1}, {2}) and surrounding text in a translation string, based on the metadata describing what each variable represents (e.g., color tags, line breaks, etc.).
Key Steps:
- Metadata Preparation:
- The function first prepares a
metadatadictionary mapping variable placeholders (like{1}) to their content (e.g.,[color=#1f8a34]).
- The function first prepares a
- Tokenization:
- It parses the input
textcharacter by character, splitting it into a queue of tokens: variables, punctuation, words, and other symbols, for example:["{1}", " Heroes ", "{2}", " arise in troubled times"].
- It parses the input
- Merging Tokens:
- It processes the token queue to merge or adjust tokens based on their type and the metadata:
- If a variable represents a color tag or similar, it merges it tightly with adjacent tokens (no extra spaces).
- If a variable is a line break (
\n), it tracks its position for later adjustment. - Punctuation and brackets are merged appropriately to avoid unwanted spaces.
- Quotation marks are handled with a stack to ensure correct pairing.
- It processes the token queue to merge or adjust tokens based on their type and the metadata:
- Reconstruction:
- The tokens are joined back into a string, with special handling to remove spaces around line breaks.
- Post-processing:
- The function replaces variable placeholders with their actual content (using
replace_variable), removes color tags (usingremove_color), and returns both the processed text and a version with color tags removed.
- The function replaces variable placeholders with their actual content (using
Detect insufficient variables
It is crucial to ensure all variables in the source text are present in the target text. If any variables are missing, it can lead to confusion and misinterpretation of the text. For example, if the source text has a variable {1} ... {2} but the target text does have {1} ... , it is not passed the validation step, we need to detect for either resubmit LLM immediately, or later resubmit, or fix manually.
def get_variable_placeholders(text):
queue = []
index = 0
while index < len(text):
if text[index] == '{':
var_start = index
# find next '}'
while index < len(text) and text[index] != '}':
index += 1
index += 1
queue.append(text[var_start+1:index-1])
else:
index += 1
return queue
def is_variable_placeholders_equal(source, target, tunit_dict):
if tunit_dict is None or len(tunit_dict) == 0:
return True, [], []
target_variables = get_variable_placeholders(target)
source_variables = get_variable_placeholders(source)
is_valid = (len(target_variables) == len(source_variables) == len(tunit_dict))
return is_valid, source_variables, target_variables
def _detect_insufficient_variable_flow(data_dict, check_source_column='source', check_target_column='target', detect_callback=None):
for key, item in data_dict.items():
target = item.get(check_target_column, None)
source = item.get(check_source_column, None)
if target is None or source is None:
continue
tunit_dict = item.get('tunit_metadata', {})
is_valid, source_variables, target_variables = is_variable_placeholders_equal(source, target, tunit_dict)
item['tunit_metadata'] = tunit_dict
if is_valid:
continue
logging.info(f"Insufficient variable detected [{key}] {source} -> {target} | {source_variables} -> {target_variables} | {tunit_dict}")
detect_callback(True) if detect_callback else None
return data_dictThe provided code snippet implements a set of functions to detect insufficient variable placeholders in translated records for a localization pipeline. Here’s an explanation of each function and their purpose:
get_variable_placeholders(): Extracts all variable placeholders (e.g., {1}, {2}) from a given text string.
- Iterates through the text, finds substrings enclosed in curly braces
{}and collects the content inside them into a list.
is_variable_placeholders_equal(): Checks if the variable placeholders in the source and target texts match, considering the translation unit metadata.
- If
tunit_dictis empty orNone, it assumes no variables need to be checked and returnsTrue. - Otherwise, it extracts variable placeholders from both source and target.
- It validates that the number of variables in the source, target, and metadata are all equal.
- Returns a boolean indicating validity, and the lists of source and target variables.
_detect_insufficient_variable_flow(): Iterates through a dictionary of translation records to detect any records where variable placeholders are missing or mismatched between source and target.
- For each record, retrieves the source and target texts and the translation unit metadata.
- Uses
is_variable_placeholders_equalto check for variable consistency. - If a mismatch is found, logs the issue and optionally triggers a callback.
- Returns the updated data dictionary.
How do we run these flow?
We will run them sequentially, and we will also keep a snapshot of the data before running the hygiene flow, so that we can compare the changes later.
def _show_hygiene_data(data_dict, snapshot_data_dict, check_column='target'):
for key, item in data_dict.items():
target = item.get(check_column, None)
snapshot_item = snapshot_data_dict[key]
snapshot_target = snapshot_item.get(check_column, None)
if target is None or snapshot_target is None:
continue
if target != snapshot_target:
logging.info(f"Hygiene [{key}] {snapshot_target} -> {target}")
snapshot_data_dict = json.loads(json.dumps(data_level_2))
data_level_2 = _process_composed_form_flow(data_level_2, check_column='target', to_column='target')
data_level_2 = _process_target_punct_flow(data_level_2, to_column='target')
data_level_2 = _detect_or_process_invalid_space_flow(data_level_2, to_column='target')
data_level_2 = _detect_insufficient_variable_flow(data_level_2, check_source_column='source', check_target_column='target')
data_level_2 = _process_variable_space_flow(data_level_2, check_column='target')
data_level_2 = _detect_punctuation_mismatch_flow(data_level_2, check_source_column='source', check_target_column='target')
_show_hygiene_data(data_level_2, snapshot_data_dict, check_column='target')
12. Save and patch to TMS
After all the hygiene processes, we will save the data to the TMS, or patch the records if you have a TMS API available. In my case, I’m simly saving the data to dataframe and later overwrite the TMS records manually.
Wrapping up
In this post, we have successfully implemented the hygiene processes for the translated records in our localization pipeline. We have cleaned up the text, converted punctuation, detected Chinese characters, adjusted spaces between variables, and detected insufficient variables. These processes are essential to ensure the quality and consistency of the translations.
What’s Next?
You might want to turn it into a visual workflow, few popular Python-based workflow frameworks to consider:
Prefect - Modern and user-friendly
- Visual dashboard to monitor your translations
- Easy retry handling for failed translations
- Simple Python decorators (
@flow,@task)
Apache Airflow - Industry standard
- Web UI to visualize your pipeline
- Schedule translations daily/weekly
- Great for production environments
Databricks - Cloud-based data platform
- Built-in support for data pipelines
- Integrates with Spark for large-scale translations
- Collaborative notebooks for team workflows
And that’s it! Thank you for following this series on LLM-powered localization pipelines. I hope you found it useful and informative. If you have any questions or suggestions, feel free to leave a comment below.
Series LLM-Powered Localization Pipeline:
