In the previous installments of this series, we established the foundation for an LLM-powered localization pipeline. In Part 2, we structured our approach further by transforming dictionary data, implementing chunking strategies, and creating translation guides to ensure consistency. We will dive into the critical elements of prompt engineering and validation – the components that determine how effectively our LLMs translate content and how we verify the quality of their output.
The Art of LLM Prompt Engineering for Translation
Let’s take a look at again the localization pipeline we are going to build, we are in step 9:
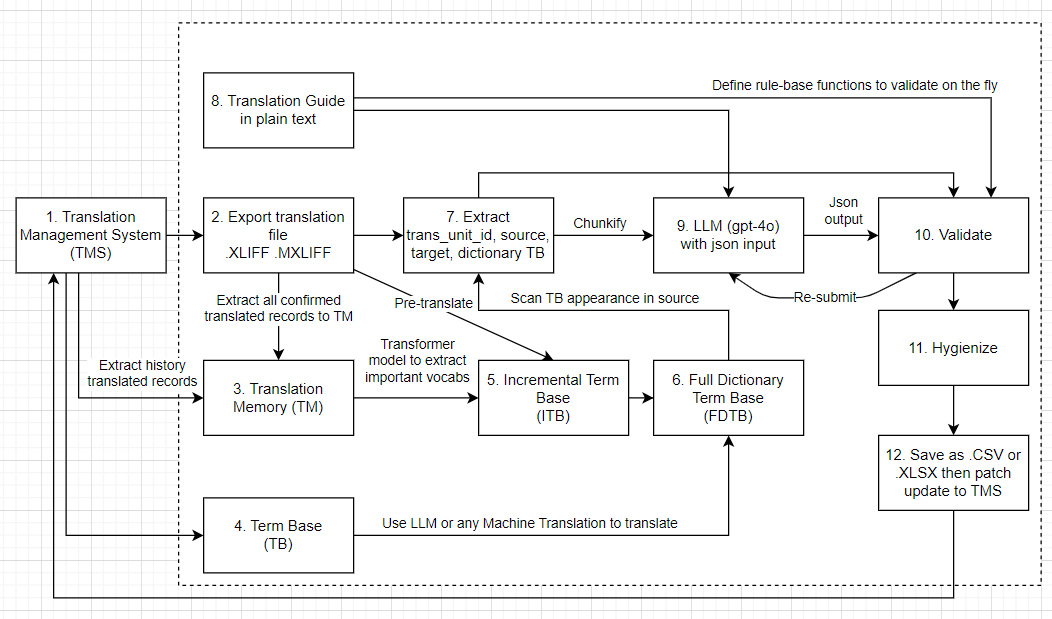
9. LLM Prompt Design and Processing
Effective prompt engineering is the cornerstone of achieving high-quality translations with LLMs. Let’s examine how to structure prompts that maximize translation accuracy and adherence to guidelines.
The Anatomy of an Effective Translation Prompt
A well-designed translation prompt should include:
- Clear instructions about the translation task
- Context for the content being translated
- Reference to the translation guide and its rules
- Examples of correct translations when helpful
- Dictionary references for key terminology
- Expected output format for consistency
Before we implement the prompt request, we need to define pydantic model for the response format:
from pydantic import BaseModel
class MXIFF_Target(BaseModel):
trans_unit_id: str
target: str
class MXIFF_Response(BaseModel):
data: list[MXIFF_Target]Here’s an example of how we might implement the post_to_llm() function mentioned in the previous post:
from openai import OpenAI, AzureOpenAI
import json
client = AzureOpenAI(
azure_endpoint = endpoint,
api_key = api_key,
api_version= api_version
)
def post_to_llm(chunk_dict, translation_guide, focus_prompt="", system_prompt=None, model="gpt-4o", number_of_tries=0):
"""
Send a chunk of translation items to the LLM for processing.
Args:
chunk_dict: Dictionary of items to translate
translation_guide: Guidelines for translation
focus_prompt: Additional instructions or feedback from previous attempts
system_prompt: System-level instructions for the LLM
model: The LLM model to use
number_of_tries: Number of previous attempts (affects temperature setting)
Returns:
List of translated items with their trans_unit_ids and target texts
"""
if system_prompt is None:
system_prompt = """
You are a professional translator specializing in accurate, context-aware translations.
Follow the translation guide precisely and maintain all formatting elements.
Generate JSON output with translated text that preserves all placeholders and special characters.
"""
# Convert chunk_dict to list format for the prompt
items_to_translate = list(chunk_dict.values())
# Build the user prompt
user_prompt = f"""
# Translation Task
Translate the following items from Chinese to English according to the translation guide below.
## Translation Guide:
{translation_guide}
## Special Instructions:
{focus_prompt if focus_prompt else "No special instructions for this batch."}
## Items to Translate:
{json.dumps(items_to_translate, indent=2, ensure_ascii=False)}
## Output Format:
Return ONLY a JSON array of objects, each with 'trans_unit_id' and 'target' fields.
Example output format:
[
{{
"trans_unit_id": "unit_123",
"target": "Translated text with {1} preserved placeholders {2}"
}}
]
"""
# Calculate temperature - decreases with more attempts for more conservative outputs
temperature = 0.2 ** (1/(number_of_tries + 1))
# Make API call to the LLM with response validation through Pydantic
response = client.beta.chat.completions.parse(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=temperature,
response_format={"type": "json_object"}
)
# Parse and validate the response using our Pydantic model
result_json = json.loads(response.choices[0].message.content)
return result_json['data']Why we increase the temperature with the number of attempts? The idea is to encourage the LLM to explore different translation options as it learns from previous mistakes. This can lead to more creative and potentially better translations over time. Whereas the focus_prompt allows us to provide specific feedback on what needs to be improved, such as correcting untranslated terms or adjusting formatting from previous attempts.
Finally the response look like this:
{
"data": [
{
"trans_unit_id": "unit_123",
"target": "Translated text with {1} preserved placeholders {2}"
}
]
}
By structuring our prompts with clear instructions, context, and examples, we enable the LLM to generate accurate and consistent translations. The use of Pydantic models for response validation ensures we get properly formatted data that can be safely processed in subsequent pipeline stages.
At the time implementing this, we were facing some content filtering issue with Azure OpenAI, which alerts us few categories have been triggered, such as “Hate Speech”, “Violence”, etc. To avoid this, we can prompt the LLM to avoid generating such content. However, we may adjust blocking higer threashold or even disable the content filtering in the API call if we are confident that our content is safe and appropriate - by filling this form https://ncv.microsoft.com/uEfCgnITdR, read more about it here https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/content-filters
Iterative Refinement Through Feedback Loops
A key advantage of our chunking approach is the ability to provide focused feedback when translations don’t meet our requirements. The focus_prompt parameter allows us to communicate specific issues to the LLM:
# Example of updating focus_prompt after validation
if not validation_result['is_valid']:
focus_prompt += f"\n- [{trans_unit_id}] When translating \"{source}\", please note: {validation_result['invalid_reason']}"
focus_prompt += f"\n- [{trans_unit_id}] Correct any Chinese terms that weren't properly translated."This feedback mechanism creates a learning loop where the LLM improves its translations based on specific guidance.
Model Selection and Parameter Tuning
Different LLM models and parameter settings can significantly impact translation quality. Some considerations:
- Temperature: Lower values (0.0-0.3) for more deterministic translations, higher values (0.7-1.0) for more creative options
- Top-p sampling: Affects diversity of word choices
- Model selection: Newer models often have better multilingual capabilities
- Context window: Larger models can handle more context at once
# Example of model and parameter selection
response = client.beta.chat.completions.parse(
model="gpt-4o", # Or gpt-4-turbo, Claude 3, etc.
messages=[...],
temperature=0.2, # Low temperature for consistency
top_p=0.95,
...
)10. Validation and Quality Assurance
Before going to validation, we may implement few plugins validation, like:
- Normalize the
targettext to NFC (Normalization Form C) to ensure consistent character representation
import unicodedata
def normalize_text(text):
# Normalize to NFC (composed form)
return unicodedata.normalize('NFC', text).strip()- Detect chinese characters in the
target
import re
CHINESE_WORD_PATTERN = re.compile(r'[\u3400-\u4dbf\u4e00-\u9fff\uf900-\ufaff]+')
def detect_chinese_with_regex(text):
# Define a regex pattern to match Chinese characters
# Find all Chinese words in the text
chinese_words = CHINESE_WORD_PATTERN.findall(text)
return chinese_words- Check placeholders in the
targetagainst thesourcetext to ensure they are preserved correctly. This is especially important for UI strings or content with dynamic elements.is_variable_placeholders_equal(source, target, tunit_dict)compares the variable placeholders in the source and target texts, using metadata fromtunit_dict. It returns whether the number and order of placeholders match between the source and target, along with the lists of detected placeholders from each.get_variable_placeholders(text)extracts all variable placeholders enclosed in curly braces{}from the given text and returns them as a list, preserving their order of appearance.
def is_variable_placeholders_equal(source, target, tunit_dict):
if tunit_dict is None or len(tunit_dict) == 0:
return True, [], []
target_variables = get_variable_placeholders(target)
source_variables = get_variable_placeholders(source)
is_valid = (len(target_variables) == len(source_variables) == len(tunit_dict))
return is_valid, source_variables, target_variables
def get_variable_placeholders(text):
queue = []
index = 0
while index < len(text):
if text[index] == '{':
var_start = index
# find next '}'
while index < len(text) and text[index] != '}':
index += 1
index += 1
queue.append(text[var_start+1:index-1])
else:
index += 1
return queueYou can add more plugins as needed in your specific use case, as it is crucial to ensure translations meet quality standards. Let’s implement a comprehensive validation function:
def validate(translation_item: MLXIFF_Target, item_data_level_2: dict) -> dict:
trans_unit_id = translation_item.get('trans_unit_id', '')
if item_data_level_2 is None or not isinstance(item_data_level_2, dict):
return {
'is_valid': False,
'invalid_reason': f"Does not match {trans_unit_id} in item_data_level_2."
}
tunit_metadata = item_data_level_2.get('tunit_metadata', {})
target = translation_item.get('target', '')
source = item_data_level_2.get('source', '')
if target is None or target.strip() == '':
return {
'is_valid': False,
'invalid_reason': "Missing translation."
}
target = normalize_text(target)
# Check for untranslated Chinese characters
chinese_words = detect_chinese_with_regex(target)
if chinese_words:
return {
'is_valid': False,
'invalid_reason': result['invalid_reason']
}
is_valid_placeholder, source_variables, target_variables = is_variable_placeholders_equal(source, target, tunit_metadata)
if not is_valid_placeholder:
return {
'is_valid': False,
'invalid_reason': f"Insufficient variable detected {source} -> {target} | {source_variables} -> {target_variables} | {tunit_metadata}"
}
return {
'is_valid': True,
'invalid_reason': ""
}The function checks whether a translated text (target) meets quality requirements when compared to its source text. It performs several validation checks:
- Verifies that the metadata reference (item_data_level_2) exists and is properly formatted
- Ensures the translation is not empty
- Normalizes the translated text for consistent processing
- Checks for untranslated Chinese characters that might have been accidentally left in the translation
- Validates that variable placeholders (like {0} or format specifiers) are correctly preserved between the source and translated text
- The function returns a dictionary with an is_valid boolean and an invalid_reason string explaining any failures.
Advanced Validation Techniques
For more sophisticated validation, consider:
- Semantic equivalence checking: Use another LLM to verify that the meaning is preserved
- Terminology consistency: Ensure dictionary terms are used consistently
- Style guide adherence: Check if translations follow stylistic rules
- Back-translation: Translate back to the source language to check for major meaning shifts
Here’s how you might implement a semantic validation check:
def validate_semantic_equivalence(source, target, source_lang, target_lang):
"""Validate semantic equivalence between source and translation."""
prompt = f"""
Evaluate if the translation preserves the meaning of the original text.
Source ({source_lang}): {source}
Translation ({target_lang}): {target}
Rate the semantic equivalence on a scale of 1-5 where:
1 = Major meaning loss or distortion
2 = Some important meaning lost
3 = Core meaning preserved but nuances lost
4 = Good preservation of meaning with minor differences
5 = Excellent equivalence in meaning
Provide your rating and explanation in JSON format:
{{
"rating": [1-5],
"explanation": "Your explanation here",
"is_acceptable": [true/false]
}}
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are an expert translation validator."},
{"role": "user", "content": prompt}
],
response_format={"type": "json_object"}
)
result = json.loads(response.choices[0].message.content)
return {
"is_valid": result.get("is_acceptable", False),
"invalid_reason": result.get("explanation", "Semantic equivalence issue") if not result.get("is_acceptable", False) else ""
}Be note that I did not use pydantic model for the response here, instead, {"type": "json_object"} is an another way to parse json.
Wrapping up
Now let’s put it all together. The overall flow integrates prompt engineering and validation in an iterative process:
- Initial translation: Submit chunks to the LLM with clear instructions
- Validation: Check each translation against quality criteria
- Feedback loop: For invalid translations, provide specific feedback
- Re-translation: Submit problematic translations with enhanced instructions
- Hygiene: Run additional plugins to correct common issues but do not need to resubmit to the LLM
In the next installment, we’ll explore how to hygienize and finalize translations, ensuring they are ready for delivery to clients or integration into applications. We’ll also discuss how to handle edge cases and maintain translation quality over time.
Series LLM-Powered Localization Pipeline:
